The cloud based e-discovery platform Everlaw is today introducing a new clustering feature, fully integrated within the Everlaw platform, that uses artificial intelligence to visualize and map large sets of documents on a scale that makes it easy to zoom from a view of the entire corpus down into a granular by-the-document view.
Everlaw says its new tool was designed to be as easy to use as navigating Google Earth.
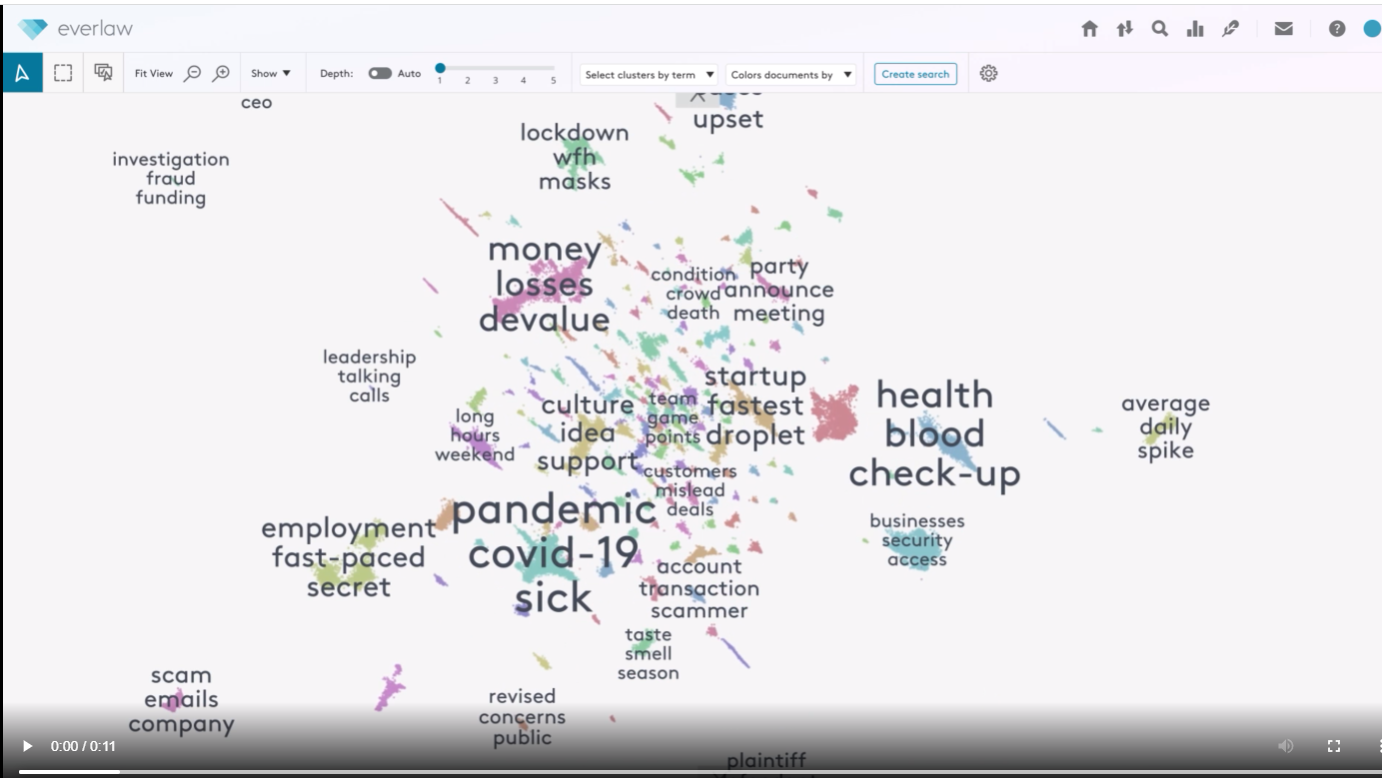
While it is common for e-discovery software to offer clustering — visual maps that group documents by concepts to help reviewers find related documents — Everlaw’s new tool has the ability to scale for the kinds of massive document sets that are increasingly common in modern litigation.
Read more about Everlaw in the LawNext Legal Technology Directory.

Everlaw’s infographic compares its clustering tool to legacy products.
If discovery is often a search for the needle in the haystack, Everlaw founder and CEO AJ Shankar told me during a demonstration, this tool allows you to map out the entire haystack and then zoom in to the individual document level, while preserving the spatial relationships among the documents, both within clusters and across clusters.
Making it easier to use than some other clustering tools on the market, Everlaw’s tool uses a design that breaks away from the spoke-and-wheel visualizations typical of these tools to use document maps in which the clusters are color coded and labeled by concepts.
As you zoom in on a concept, you begin to see the individual documents within that cluster, and can zoom to the individual document level and open the document.
Document sets can also be filtered by various parameters within the tool to show only clusters that match those parameters.
“This system is going to actually render for you on your screen, in your browser, using GPU acceleration, an entire haystack, down to the individual document level, preserved spatially, the relationships between these documents within clusters and across clusters,” Shankar said. “So you can even see which clusters are near each other and which are further away and really allow you to dig into what do you have, where should you be spending your time, what are the kinds of semantic content that are in your data?”
Besides its visual ease of use, the new tool also differs in its scale, Shankar told me. It can support up to 25 million documents on a single screen clustering dashboard. Shankar said this can be particularly useful early in e-discovery, when litigation teams are performing an early assessment of the data.
Another feature of the tool is the ability to overlay onto the clusters either human-created ratings of documents or predictive coding results so you can see where there are hot or cold documents (or documents predicted to be hot or cold, even if they have not yet been reviewed by humans) in the clusters. That might lead a reviewer to prioritize particular clusters to dive into more deeply or ignore.
Other features of this tool include:
- See clusters dynamically separate and merge based on zoom level through dynamic zoom.
- Recluster at any time.
- View the most common terms found in clusters and any transcribed A/V files.
- Filter visualization to only display a specific search.
- Access similar documents in a cluster through the context panel in the document review window.
- Open documents directly into Everlaw’s Data Visualizer.
Shankar said this tool can be used at almost any stage of discovery as a way of mapping and navigating data:
- Use it early in a case to map your own client’s data or a production from opposing counsel and identify key concepts and themese.
- Use it during review to overlay predictive coding and human-review results to find clusters of hot documents and prioritize review.
- Before making a production, use it for QA to help identify whether you’ve missed hot or privileged documents.
Developing this tool to handle large sets of documents was a huge undertaking, Shankar said.
“I will tell you, it took us an enormous amount of effort — a year-plus of engineering — to get to the scale we wanted it to, which is now 25 million-plus documents,” Shankar said.