With hallucinations continuing to haunt applications of generative AI in the legal field, Paxton AI, a startup for contract review, document drafting and legal research, today released results of a benchmarking study that showed its product achieved 93.82% average accuracy on legal research tasks.
Paxton also today released a new Confidence Indicator feature that will help its users evaluate the reliability of AI-generated responses.
To test the accuracy of its product, Paxton used a set of legal hallucination benchmarks developed by researchers at Stanford University to test the performance of public-facing large language models such as OpenAI’s ChatGPT on legal research questions.
Those researchers — all of whom also participated in the much-discussed study earlier this year of hallucinations in commercial legal research products — published the results of their study of public-facing LLMs in the paper, Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models. They also published their data for others to use for benchmarking.
Paxton used these Stanford legal hallucination benchmarks to evaluate the accuracy of its own legal AI tool, and specifically its ability to produce correct legal interpretations without errors or hallucinations.
While the Stanford data encompassed some 750,000 tasks spanning a wide variety of legal questions and scenarios and of varying levels of complexity, Paxton selected 1,600 tasks that it determined to be a representative sample of the full set of tasks.
It also excluded certain types of tasks because of “specific alignment considerations with our current testing framework,” and, in another case, due to a discrepancy between the published dataset and the metadata Paxton uses to answer questions.
Based on these benchmarks, here are the results Paxton achieved, as reported today on Paxton’s blog:
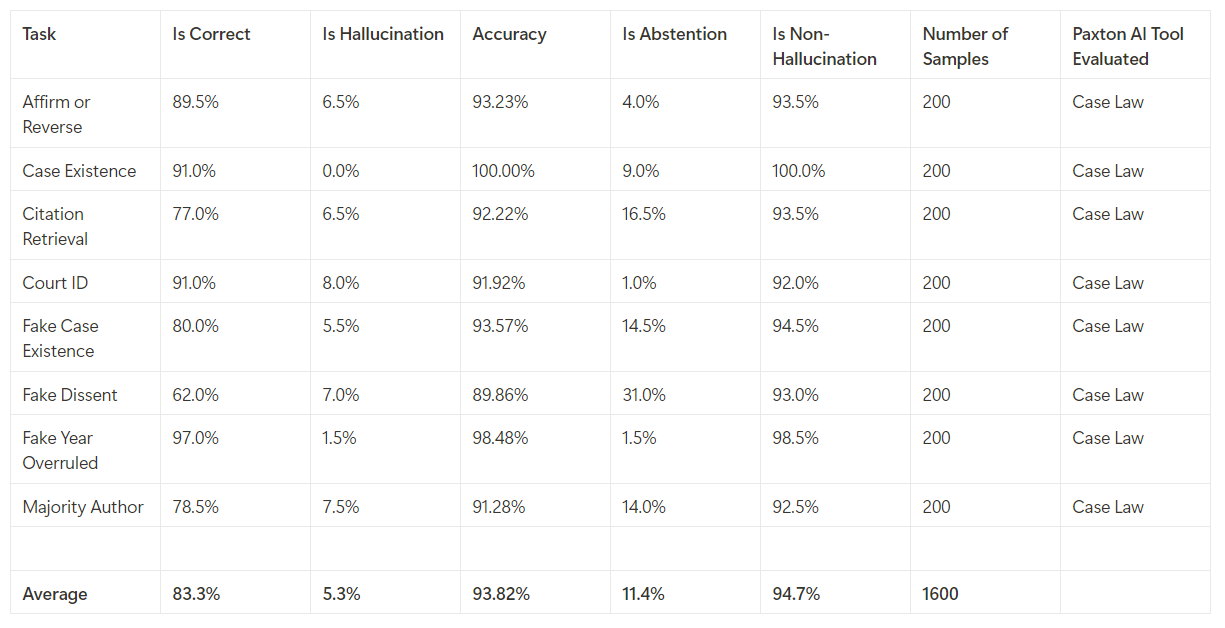
Overall, the results show that Paxton achieved an average non-hallucination rate of 94.7% and accuracy of 93.82%. In the interest of transparency, Paxton says, it is releasing the detailed results of its tests on its GitHub repository so that others can independently review its methodologies, results and performance.
Confidence Indicator
Along with today’s release of these benchmarking results, Paxton is also introducing its Confidence Indicator, a new feature that rates each answer it gives with a confidence level of low, medium or high.
While some LLMs already generate their own confidence scores, Paxton says those are not always indicative of the actual reliability or accuracy of an answer.
Its Confidence Indicator is different, it says, because it evaluates the response based on a comprehensive set of criteria, including the contextual relevance, the evidence provided, and the complexity of the query.
With this new feature, Paxton users will be able to assess the reliability of any answer Paxton delivers to their query.
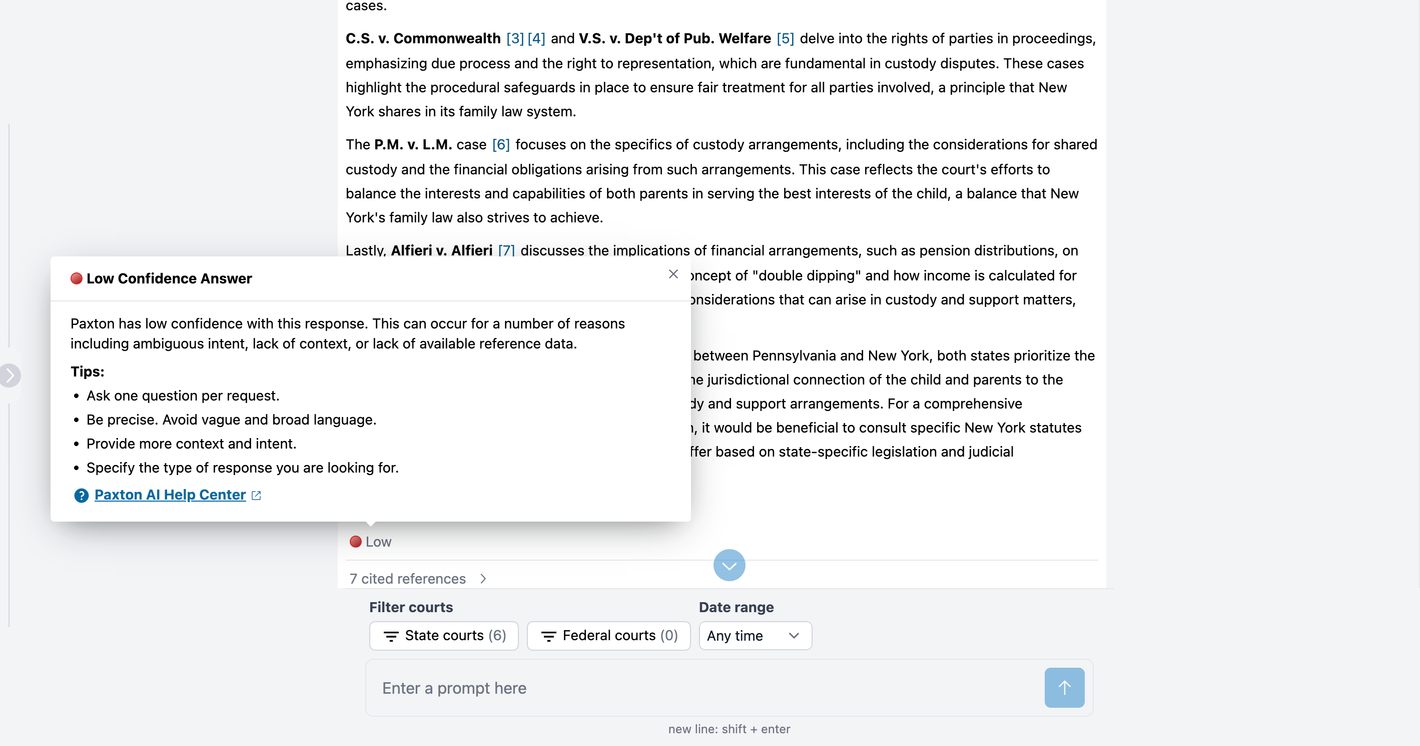
In an example provided by Paxton, a user queries:
“I need to understand family law. I am working on a serious matter. It is very important to my client. The matter is in PA and NYC. custody issue.”
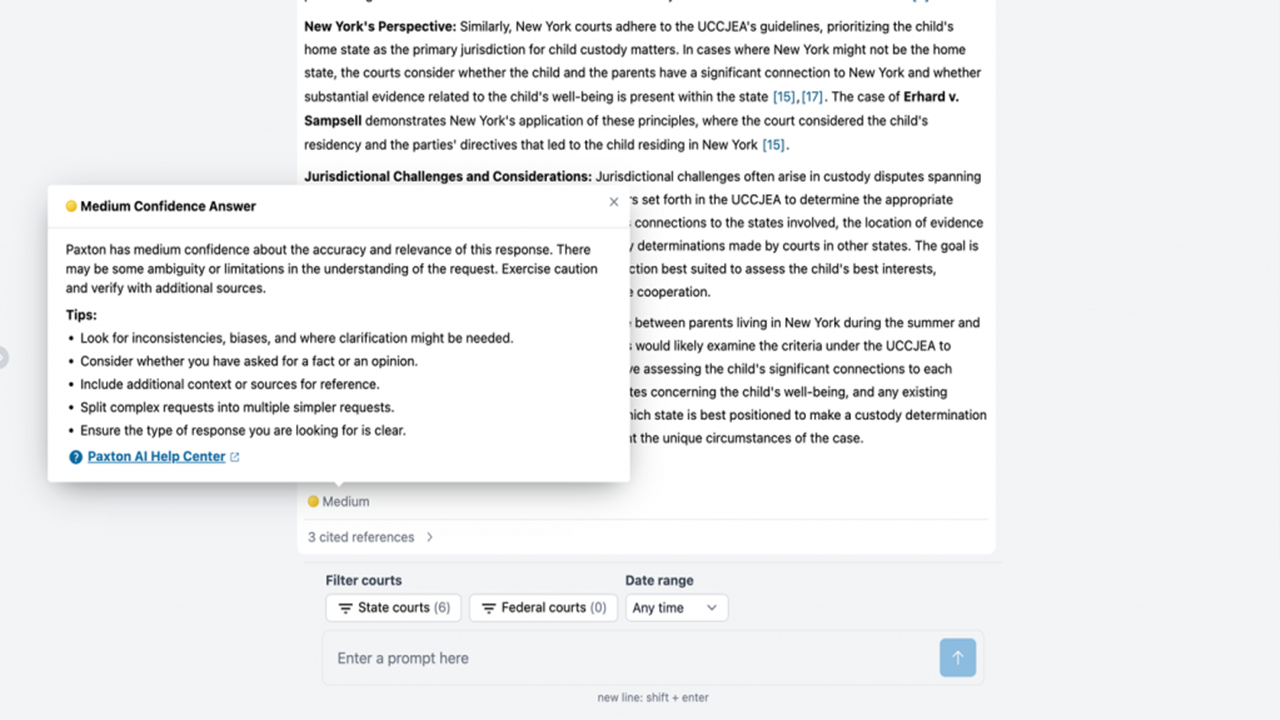
Paxton responded to the query, but because the query was vague and unfocused, Paxton indicated that it had low confidence in its response (image above). It offered suggestions for how the user could improve the query and receive a better response.
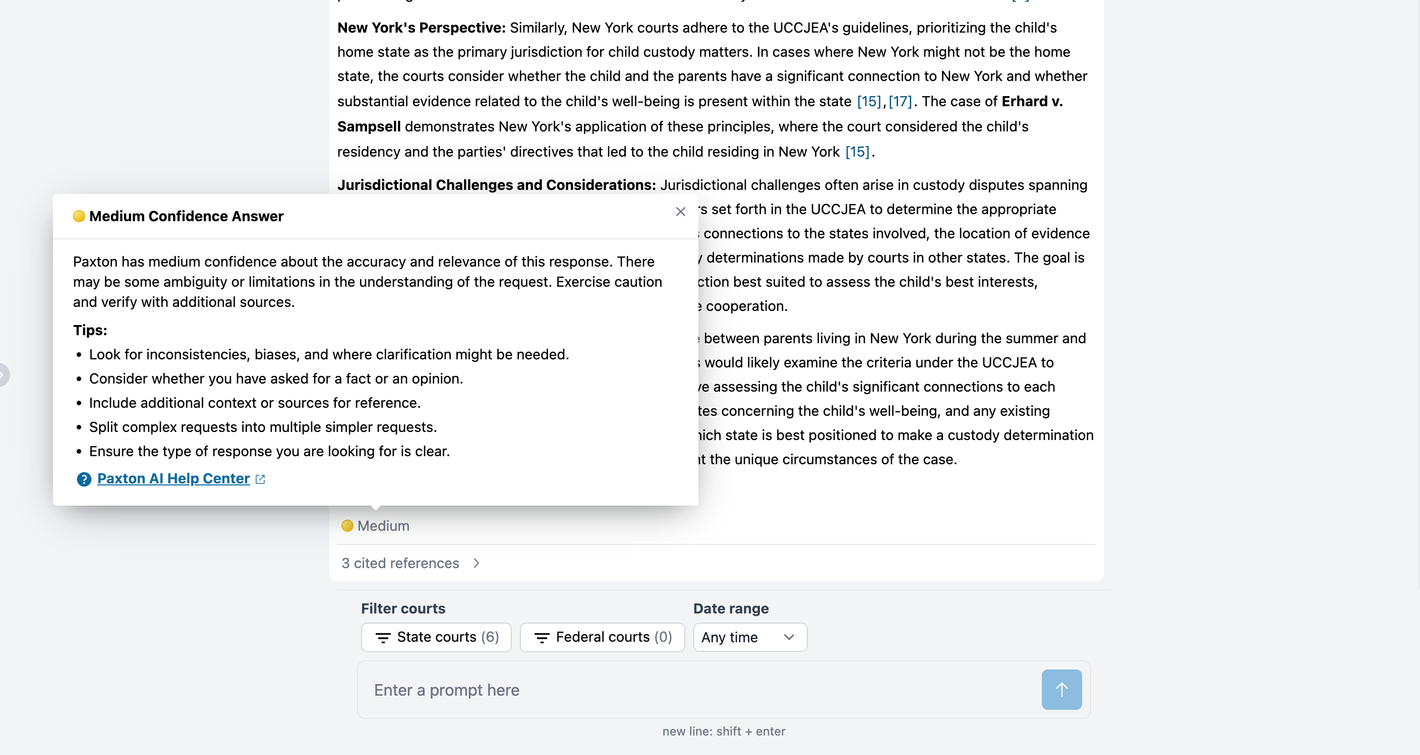
Based on that, the user revised the query to provide more detail:
“I am working on a family law matter that may implicate both NY and PA law. Mother and father are getting divorced. They live in NY in the summer and PA during the school year. The parents are having a custody dispute. I am representing the father.”
With this greater level of detail, and because the user also selected New York and Pennsylvania courts as sources, Paxton was able to increase the level of confidence in its response to medium. But because the user failed to ask a focused question, Paxon offered additional tips for getting a better answers. (Image above.)
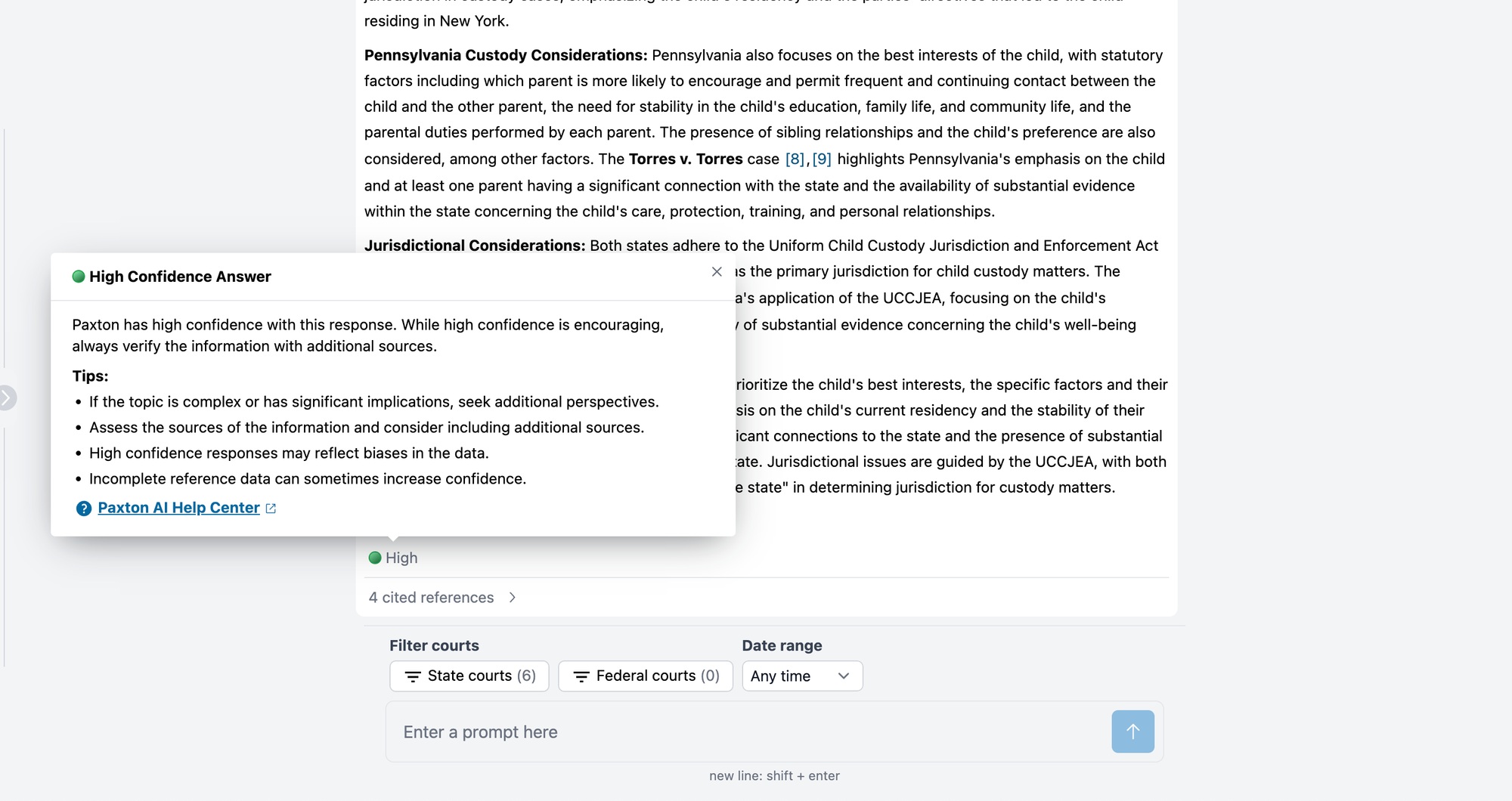
This time, the user was much more detailed:
“I am working on a family law matter that may implicate both NY and PA law. Mother and father are getting divorced, they have two children aged 12 and 15. What do courts in New York consider when determining custody? What do courts in Pennsylvania consider when determining custody? Please separate the analysis into two parts, NY and PA.”
With that level of detail, Paxton was able to provide an answer with a high level of confidence in its accuracy.
“The Paxton AI Confidence Indicator improves the user experience by quickly showing the confidence and reliability of Paxton’s AI generated responses,” the company says. “The Confidence Indicator will help speed up decision making by providing a transparent assessment of the quality of the response.”
Free Trial
Paxton is currently offering a seven-day free trial of its product, including the Confidence Indicator. After that, subscriptions start at $79 per month per user.